Aakash Ezhilan, R. Dheekksha, S. Shridevi* Centre for Advanced Data Science, Vellore Institute of Technology, Chennai, India
Download Citation:
|
Download PDF
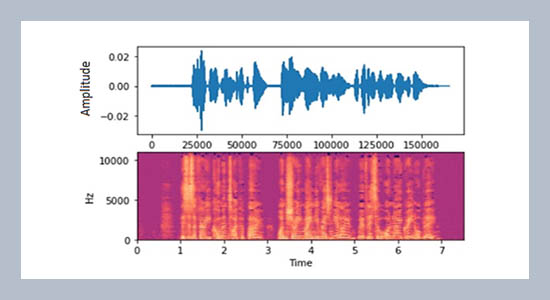
Style transfer is one of the most popular uses of neural networks. It has been thoroughly researched, such as extracting the style from famous paintings and applying it to other images thus creating synthetic paintings. Generative adversarial networks (GANs) are used to achieve this. This paper explores the many ways in which the same results can be achieved with audio related tasks, for which a plethora of new applications can be found. Analysis of different techniques used to transfer styles of audios, specifically changing the gender of the audio is implemented. The Crowd sourced high-quality UK and Ireland English Dialect speech data set was used. In this paper, the input is the male or female wave form and the opposite gender’s waveform is synthesized by the network, with the content spoken remaining the same. Different architectures are explored, from naive techniques and directly training audio waveforms against convolution neural networks (CNN) to using extensive algorithms researched for image style conversion and generation of spectrograms (using GANs) to be trained on CNNs. This research has a broader scope when used in converting music from one genre to another, identification of synthetic voices, curating voices for AIs based on preference etc.ABSTRACT
Keywords:
Style transfer, Audio analysis, Neural networks, Dialect transfer.
Share this article with your colleagues
REFERENCES
ARTICLE INFORMATION
Received:
2021-01-29
Accepted:
2021-04-07
Available Online:
2021-09-01
Ezhilan, A., Dheekksha, R., Shridevi, S. 2021. Audio style conversion using deep learning, International Journal of Applied Science and Engineering. 18, 2021034. https://doi.org/10.6703/IJASE.202109_18(5).004
Cite this article:
Copyright The Author(s). This is an open access article distributed under the terms of the Creative Commons Attribution License (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are cited.